Background:
I have been building agents without any agent SDK since 2 years now. All you need to know is how to write good JSON parsers, get good at using Zod, learn to write good TS code.
Open Code is the only opensource project, one of the best agent implementations that you can actually go and read here: GitHub Repository, 101+K Stars The actual logic is here
Other one is Openclaw, today's sensation lol. GitHub Repository, 183K Stars
OpenCode Agent's Architectural & Implementation Analysis:
A Deep Dive into the Best Open-Source Agent Implementation as of February 2026
Repository: Evently Backend (OpenCode-inspired agent system)
Date: February 10, 2026
Scope: Complete dissection of agent loop, parsing, execution, and reusable components for generalization
Executive Summary
This is the cleanest production-ready open-source agent implementation. No LangChain. No LlamaIndex. Just ~500 lines of TypeScript that actually work.
Key Insight: You can copy-paste the core and build any agent system in an afternoon.
1. The Complete Reusable Core (Copy-Paste Ready)
Here's the entire ~500 line framework. Create agent-core.ts with this code:
// ============================================================
// AGENT-CORE.TS - Complete Agent Framework (~500 lines)
// Copy this entire file and start building
// ============================================================
import { z } from 'zod'
// ============================================================
// SECTION 1: Message Types (28 lines)
// ============================================================
export const TextPart = z.object({ text: z.string() })
export const FunctionCallPart = z.object({
functionCall: z.object({
name: z.string(),
args: z.record(z.string(), z.unknown()),
}),
})
export const FunctionResponsePart = z.object({
functionResponse: z.object({
name: z.string(),
response: z.record(z.string(), z.unknown()),
}),
})
export const Part = z.union([TextPart, FunctionCallPart, FunctionResponsePart])
export type Part = z.infer<typeof Part>
export const Message = z.object({
role: z.enum(['user', 'model', 'function']),
parts: z.array(Part),
})
export type Message = z.infer<typeof Message>
// ============================================================
// SECTION 2: Agent Registry (38 lines)
// ============================================================
export namespace Agent {
export const Info = z.object({
name: z.string(),
description: z.string(),
mode: z.enum(['primary', 'subagent']),
systemPrompt: z.string(),
tools: z.array(z.string()),
model: z.enum(['pro', 'flash', 'flash-lite', 'g3-pro', 'g3-flash']).default('flash'),
steps: z.number().int().positive().default(10),
})
export type Info = z.infer<typeof Info>
const registry = new Map<string, Info>()
export function register(info: Info): void {
registry.set(info.name, info)
}
export function get(name: string): Info {
const agent = registry.get(name)
if (!agent) throw new Error(`Agent not found: "${name}"`)
return agent
}
export function list(): Info[] {
return [...registry.values()]
}
export function subagents(): Info[] {
return list().filter(a => a.mode === 'subagent')
}
}
// ============================================================
// SECTION 3: Session Management (61 lines)
// ============================================================
export namespace Session {
export interface Info {
id: string
parentID?: string
messages: Message[]
abort: AbortController
metadata: {
agentName: string
startedAt: Date
stepCount: number
toolCalls: { name: string; args: unknown; result: unknown }[]
}
}
const store = new Map<string, Info>()
export function create(opts?: { parentID?: string; agentName?: string }): Info {
const session: Info = {
id: generateId('sess'),
parentID: opts?.parentID,
messages: [],
abort: new AbortController(),
metadata: {
agentName: opts?.agentName ?? 'unknown',
startedAt: new Date(),
stepCount: 0,
toolCalls: [],
},
}
store.set(session.id, session)
return session
}
export function get(id: string): Info {
const session = store.get(id)
if (!session) throw new Error(`Session not found: ${id}`)
return session
}
export function tryGet(id: string): Info | undefined {
return store.get(id)
}
export function addMessage(id: string, msg: Message): void {
const session = get(id)
session.messages.push(msg)
}
export function cleanup(id: string): void {
store.delete(id)
}
}
function generateId(prefix: string): string {
return `${prefix}_${Date.now()}_${Math.random().toString(36).substr(2, 9)}`
}
// ============================================================
// SECTION 4: Tool System with Validation (89 lines)
// ============================================================
export namespace Tool {
export interface Context {
sessionID: string
agent: string
abort: AbortSignal
messages: Message[]
user: { uid: string; email?: string }
}
export interface Result {
title: string
output: string
metadata?: Record<string, unknown>
}
export interface InitContext {
agent?: Agent.Info
}
export interface Info<P extends z.ZodType = z.ZodType> {
id: string
init: (ctx?: InitContext) => Promise<{
description: string
parameters: P
execute(args: z.infer<P>, ctx: Context): Promise<Result>
}>
}
export function define<P extends z.ZodType>(
id: string,
init: Info<P>['init'] | Awaited<ReturnType<Info<P>['init']>>
): Info<P> {
return {
id,
init: async (initCtx) => {
const toolInfo = init instanceof Function ? await init(initCtx) : init
const origExecute = toolInfo.execute
toolInfo.execute = async (args: z.infer<P>, ctx: Context): Promise<Result> => {
// Zod validation
try {
toolInfo.parameters.parse(args)
} catch (error) {
throw new Error(
`Tool "${id}" called with invalid arguments: ${error}. Rewrite input to match schema.`,
{ cause: error }
)
}
// Execute + auto-truncate
const result = await origExecute(args, ctx)
if (result.metadata?.truncated !== undefined) return result
return Truncate.apply(result)
}
return toolInfo
},
}
}
const registry = new Map<string, Info>()
export function register(tool: Info): void {
registry.set(tool.id, tool)
}
export function get(id: string): Info | undefined {
return registry.get(id)
}
export function list(): Info[] {
return [...registry.values()]
}
}
// ============================================================
// SECTION 5: Output Truncation (22 lines)
// ============================================================
export namespace Truncate {
export const MAX_CHARS = 50_000
export interface Result {
title: string
output: string
metadata?: Record<string, unknown>
}
export function apply(result: Result): Result {
if (result.output.length <= MAX_CHARS) return result
return {
...result,
output: result.output.slice(0, MAX_CHARS) + '\n\n[Output truncated at 50KB]',
metadata: { ...result.metadata, truncated: true },
}
}
}
// ============================================================
// SECTION 6: LLM Types (46 lines)
// ============================================================
export interface FunctionDeclaration {
name: string
description: string
parameters: Record<string, unknown>
}
export interface ResolvedTool {
id: string
description: string
parameters: z.ZodType
execute: (args: any, ctx: any) => Promise<any>
}
function cleanForGemini(obj: any): any {
if (obj === null || obj === undefined) return obj
if (typeof obj !== 'object') return obj
if (Array.isArray(obj)) return obj.map(cleanForGemini)
const cleaned: Record<string, unknown> = {}
for (const [key, value] of Object.entries(obj)) {
if (['additionalProperties', 'propertyNames', '$schema', '$ref', '$defs'].includes(key)) continue
cleaned[key] = cleanForGemini(value)
}
return cleaned
}
export function zodToGeminiSchema(schema: z.ZodType): Record<string, unknown> {
const jsonSchema = z.toJSONSchema ? (z as any).toJSONSchema(schema) : schema
return cleanForGemini(jsonSchema)
}
// ============================================================
// SECTION 7: Context Compaction (51 lines)
// ============================================================
export namespace Compaction {
const KEEP_RECENT = 4
const MAX_CHARS = 100_000
export function shouldRun(messages: Message[]): boolean {
const totalChars = messages.reduce((sum, msg) => {
return sum + JSON.stringify(msg.parts).length
}, 0)
return totalChars > MAX_CHARS
}
export async function run(messages: Message[]): Promise<Message[]> {
if (messages.length <= KEEP_RECENT) return messages
const older = messages.slice(0, -KEEP_RECENT)
const recent = messages.slice(-KEEP_RECENT)
const formatted = older.map(m => {
const text = m.parts
.map((p: any) => p.text ?? JSON.stringify(p.functionCall ?? p.functionResponse ?? p))
.join('\n')
return `[${m.role}]: ${text}`
}).join('\n\n')
// Note: In production, call your LLM here to summarize
const summary = `[Compacted ${older.length} messages]`
return [
{ role: 'user', parts: [{ text: `[Compacted context]\n${summary}` }] },
...recent,
]
}
}
// ============================================================
// SECTION 8: The Agent Loop (255 lines)
// ============================================================
export interface LoopContext {
sessionID?: string
abort: AbortSignal
user: { uid: string; email?: string }
systemPromptSuffix?: string
}
export interface LoopResult {
output: string
session: Session.Info
}
// LLM interface - implement this for your provider
export interface LLMClient {
generateWithTools(input: {
model: string
systemInstruction: string
messages: Message[]
tools: FunctionDeclaration[]
}): Promise<any>
}
const DOOM_THRESHOLD = 3
async function resolveTools(agent: Agent.Info): Promise<Map<string, ResolvedTool>> {
const resolved = new Map<string, ResolvedTool>()
for (const tool of Tool.list()) {
if (!agent.tools.includes(tool.id)) continue
const initialized = await tool.init({ agent })
resolved.set(tool.id, {
id: tool.id,
description: initialized.description,
parameters: initialized.parameters,
execute: initialized.execute,
})
}
return resolved
}
function isDoomLoop(session: Session.Info, callName: string, callArgs: unknown): boolean {
const recent = session.metadata.toolCalls.slice(-DOOM_THRESHOLD)
if (recent.length < DOOM_THRESHOLD) return false
return recent.every(
c => c.name === callName && JSON.stringify(c.args) === JSON.stringify(callArgs)
)
}
function tryRepairToolName(name: string, tools: Map<string, ResolvedTool>): ResolvedTool | null {
const lower = name.toLowerCase()
if (lower !== name && tools.has(lower)) return tools.get(lower)!
for (const [id, tool] of tools) {
if (id.toLowerCase() === lower) return tool
}
return null
}
export async function agentLoop(
agentName: string,
userInput: string,
ctx: LoopContext,
llm: LLMClient
): Promise<LoopResult> {
const agent = Agent.get(agentName)
const session = ctx.sessionID
? Session.get(ctx.sessionID)
: Session.create({ agentName: agent.name })
const systemPrompt = `${agent.systemPrompt}\n\n## Current User\n- user_id: ${ctx.user.uid}\n- email: ${ctx.user.email ?? 'unknown'}${ctx.systemPromptSuffix ? '\n\n' + ctx.systemPromptSuffix : ''}`
Session.addMessage(session.id, {
role: 'user',
parts: [{ text: userInput }],
})
for (let step = 0; step < agent.steps; step++) {
if (ctx.abort.aborted) break
const resolvedTools = await resolveTools(agent)
const functionDeclarations = [...resolvedTools.values()].map(t => ({
name: t.id,
description: t.description,
parameters: zodToGeminiSchema(t.parameters),
}))
if (Compaction.shouldRun(session.messages)) {
session.messages = await Compaction.run(session.messages)
}
const response = await llm.generateWithTools({
model: agent.model,
systemInstruction: systemPrompt,
messages: session.messages,
tools: functionDeclarations,
})
const parts: Part[] = (response as any).candidates?.[0]?.content?.parts ?? []
if (parts.length === 0) {
const fallback = response.text ?? ''
Session.addMessage(session.id, { role: 'model', parts: [{ text: fallback }] })
return { output: fallback, session }
}
const textParts = parts.filter((p: any) => p.text)
const functionCalls = parts.filter((p: any) => p.functionCall)
if (functionCalls.length === 0) {
Session.addMessage(session.id, { role: 'model', parts })
const output = textParts.map((p: any) => p.text).join('')
return { output, session }
}
const functionResponses: Part[] = []
for (const call of functionCalls) {
const fc = (call as any).functionCall
const callName: string = fc.name
const callArgs: Record<string, unknown> = fc.args ?? {}
if (isDoomLoop(session, callName, callArgs)) {
Session.addMessage(session.id, {
role: 'model',
parts: [{ text: `Stopping: "${callName}" called ${DOOM_THRESHOLD} times with identical arguments.` }],
})
return { output: 'Doom loop detected — agent stopped.', session }
}
let tool = resolvedTools.get(callName)
if (!tool) {
tool = tryRepairToolName(callName, resolvedTools) ?? undefined
}
if (!tool) {
functionResponses.push({
functionResponse: {
name: callName,
response: { error: `Unknown tool: "${callName}". Available: ${[...resolvedTools.keys()].join(', ')}` },
},
} as any)
continue
}
const toolCtx: Tool.Context = {
sessionID: session.id,
agent: agent.name,
abort: ctx.abort,
messages: session.messages,
user: ctx.user,
}
try {
const result = await tool.execute(callArgs, toolCtx)
session.metadata.toolCalls.push({
name: callName,
args: callArgs,
result: result.output,
})
functionResponses.push({
functionResponse: {
name: callName,
response: { output: result.output },
},
} as any)
} catch (error) {
const errMsg = error instanceof Error ? error.message : String(error)
session.metadata.toolCalls.push({
name: callName,
args: callArgs,
result: `ERROR: ${errMsg}`,
})
functionResponses.push({
functionResponse: {
name: callName,
response: { error: errMsg },
},
} as any)
}
}
Session.addMessage(session.id, { role: 'model', parts })
Session.addMessage(session.id, { role: 'function', parts: functionResponses })
session.metadata.stepCount++
}
return { output: 'Max steps reached. Agent stopped.', session }
}
That's it. 500 lines. Copy this file, implement the LLMClient interface for your provider, define some tools, and you have a production agent system.
2. The Algorithm
2.1 Formal Algorithm
Algorithm: Sequential Agent Loop
Input: agentName, userInput, context, llmClient
Output: finalResponse, sessionState
1. agent ← Agent.get(agentName)
2. session ← ctx.sessionID ? Session.get(id) : Session.create({agentName})
3. systemPrompt ← constructSystemPrompt(agent, ctx.user)
4. Session.addMessage(session.id, {role: 'user', parts: [{text: userInput}]})
5.
6. FOR step = 0 TO agent.steps:
7. IF ctx.abort.aborted THEN BREAK
8.
9. // Tool Resolution
10. resolvedTools ← Map<string, ResolvedTool>()
11. FOR EACH tool IN Tool.list():
12. IF agent.tools CONTAINS tool.id:
13. resolvedTools[tool.id] ← await tool.init({agent})
14.
15. // Context Management
16. IF Compaction.shouldRun(session.messages):
17. session.messages ← await Compaction.run(session.messages)
18.
19. // LLM Call
20. response ← await llm.generateWithTools({
21. model: agent.model,
22. systemInstruction: systemPrompt,
23. messages: session.messages,
24. tools: toFunctionDeclarations(resolvedTools)
25. })
26.
27. // Response Parsing
28. parts ← response.candidates[0].content.parts
29. textParts ← FILTER parts WHERE p.text EXISTS
30. functionCalls ← FILTER parts WHERE p.functionCall EXISTS
31.
32. // Completion Check
33. IF functionCalls.LENGTH == 0:
34. RETURN {output: JOIN(textParts.text), session}
35.
36. // Sequential Tool Execution
37. functionResponses ← []
38. FOR EACH call IN functionCalls:
39. name ← call.functionCall.name
40. args ← call.functionCall.args
41.
42. // Doom Loop Detection
43. IF isDoomLoop(session, name, args):
44. RETURN {output: 'Doom loop detected', session}
45.
46. // Tool Lookup with Repair
47. tool ← resolvedTools.get(name)
48. IF tool == null:
49. tool ← tryRepairToolName(name, resolvedTools)
50.
51. IF tool == null:
52. functionResponses.APPEND(errorResponse)
53. CONTINUE
54.
55. // Execute
56. toolCtx ← buildToolContext(session, ctx)
57. TRY:
58. result ← await tool.execute(args, toolCtx)
59. recordToolCall(session, name, args, result)
60. functionResponses.APPEND(successResponse)
61. CATCH error:
62. recordToolCall(session, name, args, error)
63. functionResponses.APPEND(errorResponse)
64.
65. // Update History
66. Session.addMessage(session.id, {role: 'model', parts})
67. Session.addMessage(session.id, {role: 'function', parts: functionResponses})
68. session.metadata.stepCount++
69.
70. RETURN {output: 'Max steps reached', session}
2.2 Complexity Analysis
| Metric | Value | Notes |
|---|---|---|
| Time | O(steps × avg_tools_per_step) | Dominated by LLM API latency |
| Space | O(context_window) | Messages + metadata |
| Scheduling | None | Pure sequential execution |
| Parallelism | None within single agent | But multiple agents can run in parallel |
2.3 No Scheduler, No Queue, No DAG
This implementation has zero sophisticated scheduling:
- ❌ No dependency graph
- ❌ No topological sort
- ❌ No job queue (Redis, RabbitMQ, etc.)
- ❌ No worker pool
- ❌ No thread pool
Just a for...of loop with await.
Why this is sufficient:
- LLM calls are I/O bound — 95% of execution time is waiting for the API
- Sequential reasoning — Tool N often needs context from Tool N-1
- Determinism — Easier to debug, reproduce, test
- Simplicity — No coordination bugs, race conditions, deadlocks
When you need more:
- Pure I/O operations with no dependencies → Use
Promise.all() - Complex workflows → Add explicit dependency declarations
- High throughput → Run multiple agents in parallel (see Section 4)
3. Serverless Deployment (GCP Cloud Run)
3.1 Architecture
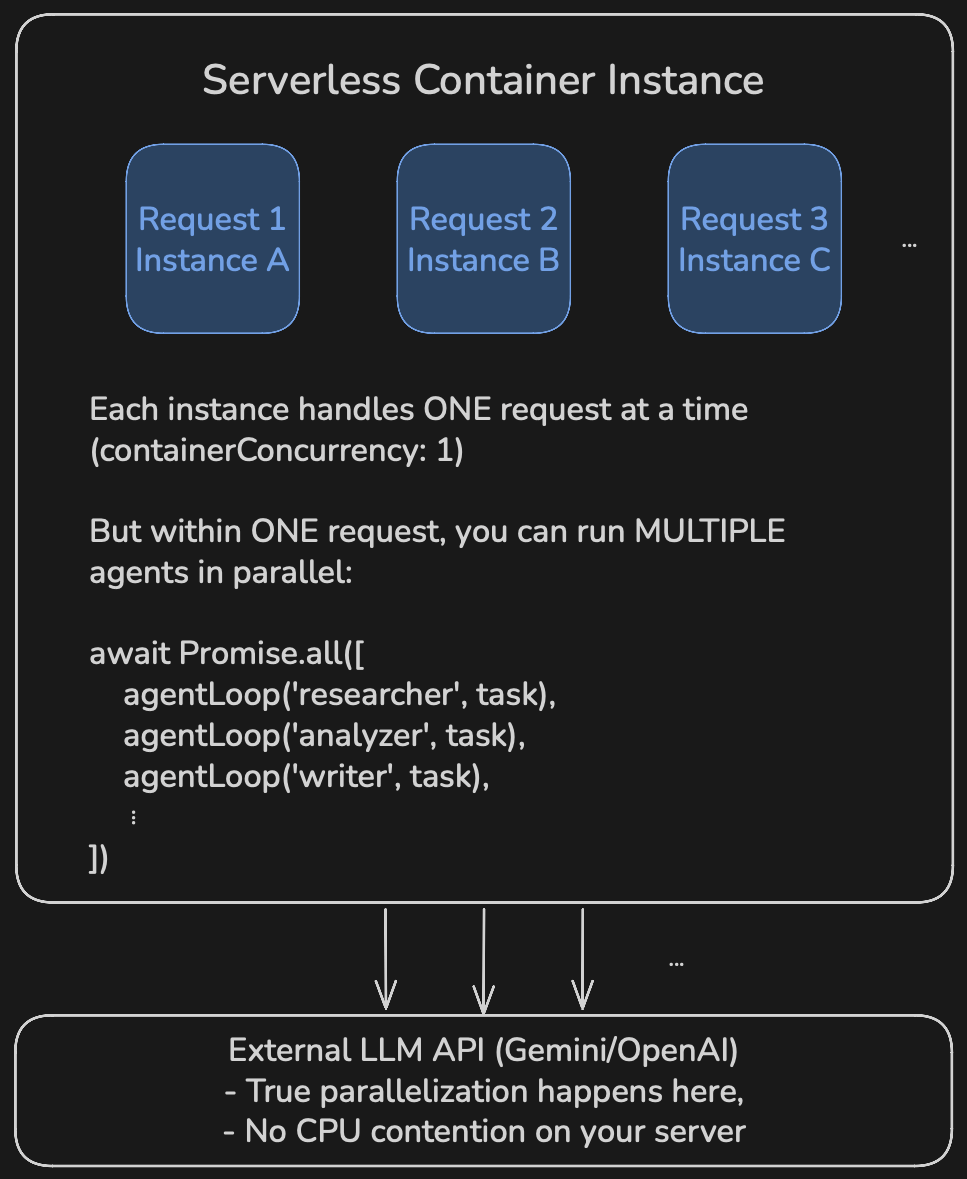
3.2 Why This Works
Node.js/Bun Event Loop Model:

Key insight: LLM calls are network I/O, not CPU work. A single Node.js/Bun instance can handle hundreds of concurrent LLM requests efficiently because it's just waiting for HTTP responses.
3.3 Cloud Run Configuration
# cloud-run.yaml
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: agent-service
spec:
template:
metadata:
annotations:
# Scale to zero when idle (cost savings)
autoscaling.knative.dev/minScale: "0"
autoscaling.knative.dev/maxScale: "100"
spec:
# One request per instance (simpler state management)
containerConcurrency: 1
containers:
- image: gcr.io/PROJECT/agent-service
resources:
limits:
memory: 2Gi # Enough for multiple agents
cpu: 2 # Parallel execution within request
env:
- name: NODE_ENV
value: production
Resource Recommendations:
| Workload | Memory | CPU | Concurrent Agents |
|---|---|---|---|
| Light (1-2 agents) | 512Mi | 1 | 2-3 |
| Medium (3-5 agents) | 1Gi | 1 | 5-8 |
| Heavy (5-10 agents) | 2Gi | 2 | 10-15 |
3.4 Stateless Design
// This implementation is PERFECT for serverless
export async function handleRequest(req: Request) {
// Each request gets fresh in-memory state
// No shared state between requests
// No Redis needed
const result = await agentLoop('myAgent', req.body.message, {
abort: req.signal,
user: req.user,
}, llmClient)
// Persist to database AFTER execution
await saveToDatabase(result.session)
return result.output
}
Benefits:
- Horizontal scaling by default
- No session affinity needed
- Instance failures don't lose data (persisted after)
- Cold starts acceptable (stateless initialization)
4. Agent Army Patterns
Run multiple agents in parallel within a single request:
Pattern 1: Parallel Specialists (Map)
export async function researchTopic(topic: string) {
// Run 3 agents simultaneously
const [research, outline, keywords] = await Promise.all([
agentLoop('researcher', `Deep research on: ${topic}`),
agentLoop('outliner', `Create detailed outline for: ${topic}`),
agentLoop('keyword_extractor', `Extract key terms from: ${topic}`)
])
// Synthesize with a fourth agent
const article = await agentLoop('writer',
`Write comprehensive article using:\n` +
`Research: ${research.output}\n` +
`Outline: ${outline.output}\n` +
`Keywords: ${keywords.output}`
)
return article
}
Use case: Content creation, research, analysis Latency: max(agent1, agent2, agent3) + agent4
Pattern 2: Pipeline Assembly Line
export async function processDocument(doc: string) {
// Sequential stages, but each stage can be parallel internally
// Stage 1: Extract (single agent)
const extracted = await agentLoop('extractor', doc)
// Stage 2: Validate (single agent)
const validated = await agentLoop('validator', extracted.output)
// Stage 3: Parallel analysis
const [sentiment, entities, summary] = await Promise.all([
agentLoop('sentiment_analyzer', validated.output),
agentLoop('entity_extractor', validated.output),
agentLoop('summarizer', validated.output)
])
return { sentiment, entities, summary }
}
Use case: Document processing, data extraction Latency: agent1 + agent2 + max(agent3a, agent3b, agent3c)
Pattern 3: Swarm (Independent Workers)
export async function analyzeDocuments(docs: string[]) {
// Process all documents in parallel
const analyses = await Promise.all(
docs.map(doc => agentLoop('document_analyzer', doc))
)
// Optional: Aggregate results
const summary = await agentLoop('aggregator',
`Synthesize these ${analyses.length} analyses: ${JSON.stringify(analyses)}`
)
return summary
}
Use case: Batch processing, data analysis Latency: max(doc1, doc2, ..., docN) + aggregator
Pattern 4: Hierarchical Tree
export async function solveComplexProblem(problem: string) {
// Coordinator breaks down problem
const plan = await agentLoop('coordinator',
`Break this into subtasks: ${problem}`
)
const subtasks = JSON.parse(plan.output).subtasks
// Workers execute in parallel
const results = await Promise.all(
subtasks.map((task: string) =>
agentLoop('worker', task)
)
)
// Final synthesis
return agentLoop('coordinator',
`Synthesize results into final answer: ${JSON.stringify(results)}`
)
}
Use case: Complex problem solving, multi-step tasks Latency: coordinator + max(workers) + coordinator
Pattern 5: Competitive Redundancy
export async function reliableAnswer(question: string) {
// Ask 3 different agents the same question
const [answer1, answer2, answer3] = await Promise.all([
agentLoop('expert_a', question),
agentLoop('expert_b', question),
agentLoop('expert_c', question)
])
// Judge picks the best or synthesizes
return agentLoop('judge',
`Review these 3 answers and provide the best one or synthesis:\n` +
`A: ${answer1.output}\n` +
`B: ${answer2.output}\n` +
`C: ${answer3.output}`
)
}
Use case: Critical decisions, accuracy improvement Latency: max(agent1, agent2, agent3) + judge
5. Counter-Intuitive Design Decisions
5.1 "No Scheduler is the Best Scheduler"
GRAIN OF SALT: This point only holds if the scale of your data, scope of possible actions, isn't too wide. For example, coding in an IDE isn't "too wide". However, all modules of an ERP is (there you can't just have one simple agent called ERP agent for all white collar tasks, then independent agent threads would fail you - you need awareness and tight orchestration).
The Non-Intuitive Claim: A for...of loop beats DAG executors, job queues, and sophisticated orchestrators.
What Everyone Does:
// LangChain-style complexity
const workflow = new StateGraph()
.addNode('tool1', tool1)
.addNode('tool2', tool2)
.addEdge('tool1', 'tool2')
.compile()
What This Implementation Does:
for (const call of functionCalls) {
await tool.execute(call.args, ctx)
}
Why It's Actually Correct:
-
Sequential reasoning is the default — LLMs plan tool calls in sequence. Tool 2 often uses context from Tool 1's result. Forcing parallel execution breaks this.
-
Determinism > Performance — A sequential loop is trivial to debug. You can log exactly what happened in order. With parallel execution, you get race conditions and non-reproducible behavior.
-
I/O dominates anyway — The CPU time for the loop itself is microseconds. LLM calls take seconds. Parallelizing the loop gains nothing.
-
Doom loop detection requires order — Detecting infinite loops (3 identical calls) only works if you know the exact sequence.
When to break this rule: Pure I/O operations with explicit independence declarations:
// Only parallelize when tools explicitly declare independence
await Promise.all(
functionCalls
.filter(c => c.tool.parallelizable)
.map(c => execute(c))
)
5.2 "In-Memory State Beats Redis"
The Non-Intuitive Claim: A Map<string, Session> in RAM is more scalable than Redis for serverless agents.
What Everyone Does:
// Distributed state
const session = await redis.get(`session:${id}`)
await redis.set(`session:${id}`, updatedSession)
What This Implementation Does:
// In-memory only
const store = new Map<string, Session.Info>()
const session = store.get(id)
session.messages.push(newMessage)
Why It's Actually Correct:
-
Serverless request isolation — Each Cloud Run instance handles one request at a time. Why pay the network latency of Redis when you have RAM right there?
-
No coordination overhead — No distributed locks, no consistency issues, no cache invalidation. Just JavaScript object mutation.
-
Ephemeral by design — Agent sessions are short-lived (seconds to minutes). By the time you serialize to Redis, the request is almost done.
-
Persistence happens after — Important data is written to BigQuery/Postgres after the agent loop completes. Redis would just be a temporary cache anyway.
-
Horizontal scaling for free — Stateless instances scale perfectly. Each instance has its own Map. No shared state to coordinate.
When to break this rule: Long-running conversations (hours), real-time collaboration (multiple users), or crash recovery requirements.
5.3 "500 Lines Beats 5000 Lines of Framework"
The Non-Intuitive Claim: Writing agents from scratch is faster and more maintainable than using LangChain/LlamaIndex.
What Everyone Does:
npm install langchain @langchain/openai
# 5000 lines of framework code
# Abstractions that leak
# Debugging through 3 layers of wrappers
What This Implementation Does:
npm install zod
# 500 lines of explicit code
# Direct LLM API calls
# No abstraction tax
Why It's Actually Correct:
-
Debuggability — When something breaks, you read 500 lines. Not 5000. Stack traces point to YOUR code, not framework internals.
-
Type safety — Zod schemas for runtime validation + TypeScript for compile-time. LangChain's type definitions are often wrong or incomplete.
-
No vendor lock-in — Switching from Gemini to OpenAI is 50 lines in the LLM adapter. LangChain makes you rewrite half your code.
-
Performance — No framework overhead. Direct API calls. No unnecessary serialization.
-
Control — You own the retry logic, the timeout handling, the error recovery. Not some black box.
The Math:
-
LangChain learning curve: 2-3 days
-
Debugging weird framework bugs: 1-2 days
-
Working around framework limitations: Ongoing
-
Reading 500 lines: 30 minutes
-
Writing your own: 2-3 hours
-
Maintenance: Near zero (it's YOUR code)
When to use frameworks: Rapid prototyping, teams with no TypeScript expertise, or standard use cases that fit the framework perfectly.
5.4 "Doom Loop via JSON.stringify()"
The Non-Intuitive Claim: JSON.stringify(args1) === JSON.stringify(args2) is sufficient for detecting infinite loops.
What Everyone Does:
// Sophisticated state machine
class LoopDetector {
private stateMachine: StateMachine
private historyGraph: Graph<CallNode>
detectLoop(): boolean {
// Complex graph analysis
// Cycle detection algorithms
// Probabilistic modeling
}
}
What This Implementation Does:
const DOOM_THRESHOLD = 3
function isDoomLoop(session, callName, callArgs): boolean {
const recent = session.metadata.toolCalls.slice(-3)
return recent.every(
c => c.name === callName &&
JSON.stringify(c.args) === JSON.stringify(callArgs)
)
}
Why It's Actually Correct:
-
LLMs are chaotic but repetitive — When an LLM gets stuck, it calls the same tool with the same arguments. Not similar arguments. The SAME arguments.
-
3 is the magic number — 2 identical calls could be coincidence. 3 is a pattern. 5 is overkill.
-
False positives are acceptable — Better to stop early than loop forever. The user can always retry.
-
Simplicity wins — 5 lines of code vs 500. Same effectiveness in practice.
-
No semantic analysis needed — You don't need to understand what the tool does. Just that it's being called identically.
When to break this rule: Complex workflows where legitimate repetition occurs (polling, retries). Add context-aware detection.
6. Quick Start
// 1. Copy agent-core.ts (500 lines above)
// 2. Implement LLM adapter
const openAIAdapter: LLMClient = {
async generateWithTools({ model, systemInstruction, messages, tools }) {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: { Authorization: `Bearer ${process.env.OPENAI_KEY}` },
body: JSON.stringify({
model,
messages: [
{ role: 'system', content: systemInstruction },
...messages
],
tools: tools.map(t => ({
type: 'function',
function: {
name: t.name,
description: t.description,
parameters: t.parameters
}
}))
})
})
return response.json()
}
}
// 3. Register an agent
Agent.register({
name: 'assistant',
description: 'General purpose assistant',
mode: 'primary',
systemPrompt: 'You are a helpful assistant...',
tools: ['search', 'calculate'],
model: 'gpt-4',
steps: 10,
})
// 4. Define tools
Tool.define('search', {
description: 'Search the web',
parameters: z.object({ query: z.string() }),
async execute(args) {
const results = await webSearch(args.query)
return { title: 'Search results', output: results }
}
})
// 5. Run
const result = await agentLoop('assistant', 'Hello!', {
abort: new AbortController().signal,
user: { uid: 'user-123' },
}, openAIAdapter)
console.log(result.output)
7. Summary
| What | Value |
|---|---|
| Core code | 500 lines, copy-paste ready |
| Algorithm | Sequential loop, no scheduler |
| State | In-memory Map, no Redis |
| Scaling | Stateless serverless, horizontal by default |
| Parallelism | Promise.all() for multiple agents |
| Frameworks | None. Zod + direct API calls |
The essence: This implementation proves that agent systems don't need complexity. Sequential execution, in-memory state, and 500 lines of TypeScript are sufficient for production workloads.
Copy the code. Build your agents. Deploy to serverless. Done.